Analyzing Cyberpunk 2077 Related Tweets using Twitter Streaming API and Apache Flink
Ever since I first used Apache Flink, I always wanted to use it with the Twitter Streaming API, and for the subject I chose Cyberpunk 2077. I’m also hyped about Cyberpunk 2077, and while waiting for the release, playing with Flink looked awesome to me. Most of the necessary libraries are already present and ready in Maven Central.
Before any tweets can flow, the Twitter Streaming API wants application tokens. I got lucky here: I have a developer account and spun up a few apps a couple of years ago, and since Twitter still honors those older apps, I didn’t have to apply for a fresh one. Any future apps will need an application though (a todo for me).
The first piece to stand up was Flink itself. I ran the job manager and task manager components on a single instance with Docker, simply following the official guide here: https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/resource-providers/standalone/docker.html#start-a-session-cluster to create a Session Cluster. It was pleasantly straightforward, and the nice part is that adding capacity later is just a matter of deploying another taskmanager onto the same network as the rest of the components. With that, Flink is ready and waiting for our code.
Next came the stream itself. I followed the Twitter Connector guide to write the configuration that wires it up: https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/twitter.html and soon the datastream was live and pulling in tweets. Not all of them are wanted, though. Retweets, for one: the Twitter API delivers RTs as if they were brand new tweets, carrying the “RT” keyword like "RT @OriginalTweetOwner Hey @CyberPunkGame...". Since we already have the original tweet, there’s no reason to keep the RTs around. To stay on topic, I set the track field to the cyberpunk and cyberpunk 2077 keywords as the Twitter Stream API documentation describes, and then dropped anything unrelated with Flink’s FilterFunction.
Side note: Twitter also publishes deleted tweets in this Streaming API, and consumers have to follow this message and delete the relevant tweets on their side as well.
With the data filtered and shaped into our desired DTO, the next question is where to put it so we can actually analyze it. I went with Elasticsearch, which is a convenient fit because Flink ships ready-made Elasticsearch sinks.
ElasticsearchSink.Builder<MyDTO> esSinkBuilder = new ElasticsearchSink.Builder<>(
HttpHost,
new ElasticsearchSinkFunction<MyDTO>() {
public IndexRequest createIndexRequest(MyDTO element)
...
...
.filter(new FilterFunction<TwitterData>() {
public boolean filter(TwitterData data) throws Exception {
if (data.getUser() != null) {
return true
} ..
}
})
The local build and testing looked good, so all that remained was getting the JAR onto Flink. I uploaded it and set the necessary parameters through the UI, and with the job running, we can finally check the data landing in Elasticsearch.
To make sense of it, I built a few visualizations and pulled them into a Dashboard. The picture below shows the last 24h of data in Kibana. Yep, the most used keywords besides Cyberpunk are RTX and 3080, and when checking the tweets, it seems there was a giveaway using those tags.
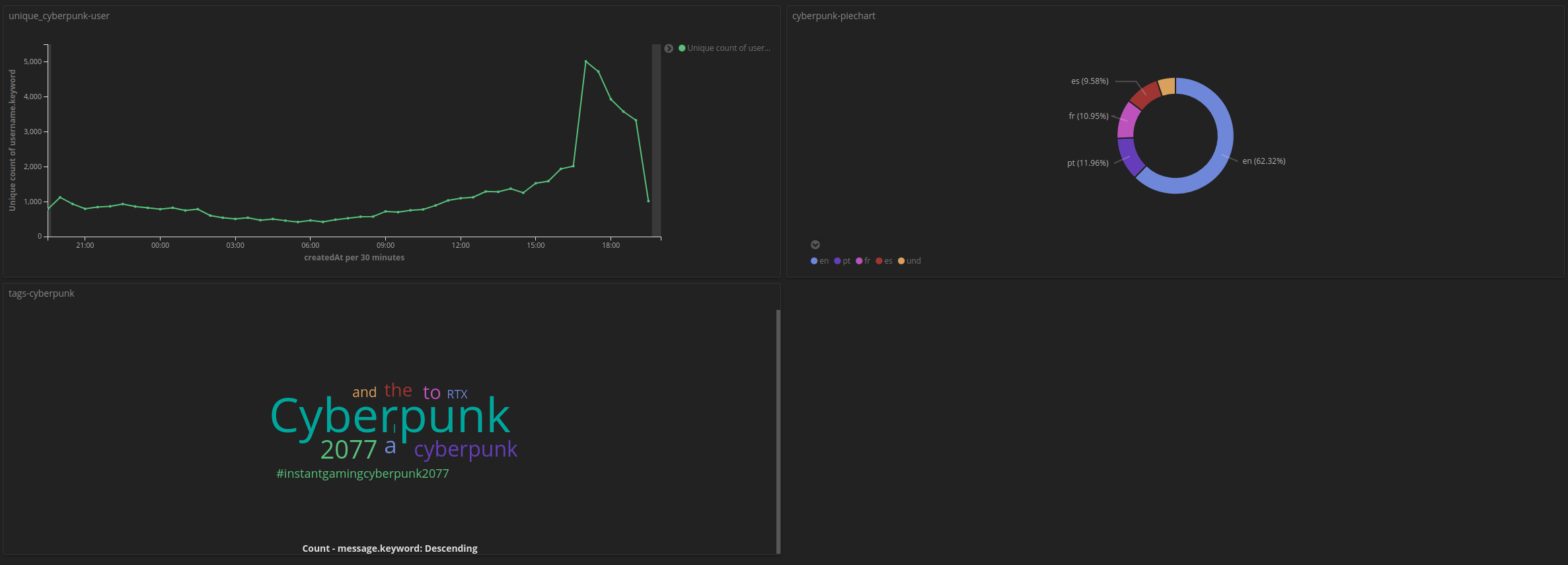
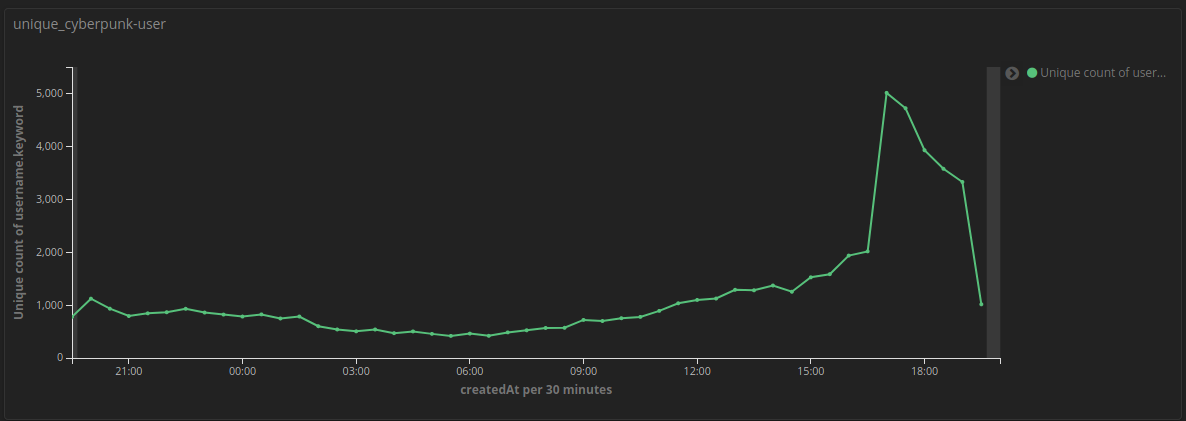
In the picture below, we can see the unique tweet senders, and it peaked at around 16:00 GMT because Cyberpunk 2077 preloading started at that time.
We can also see that the most used languages are English, Portuguese, French, and Spanish, according to the last 24h of data.
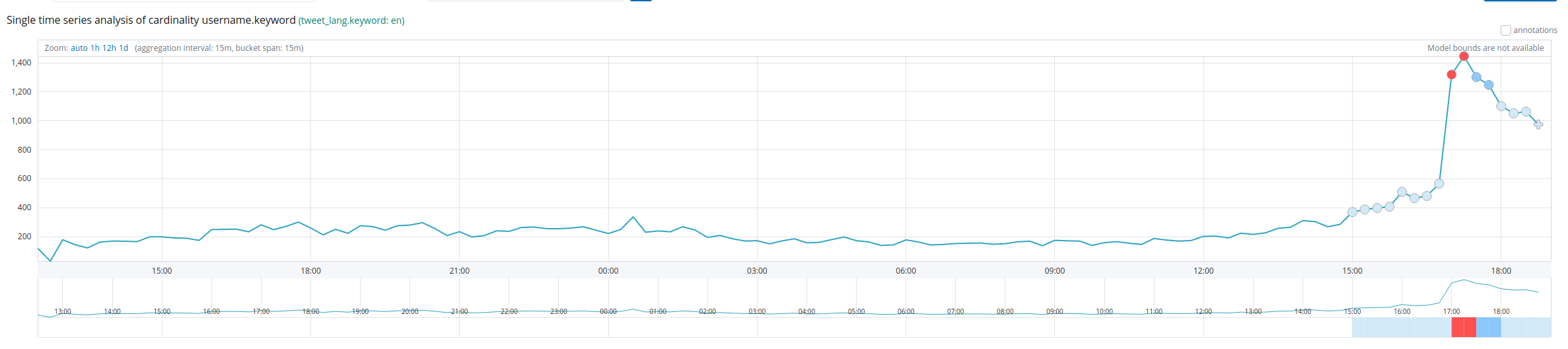
Elasticsearch X-Pack goes a step further with Machine Learning and Anomaly Detection features, available on a 30-day trial, so I gave them a spin too. The picture below breaks unique tweet senders down by tweet language, and the detector flagged an anomaly in it.
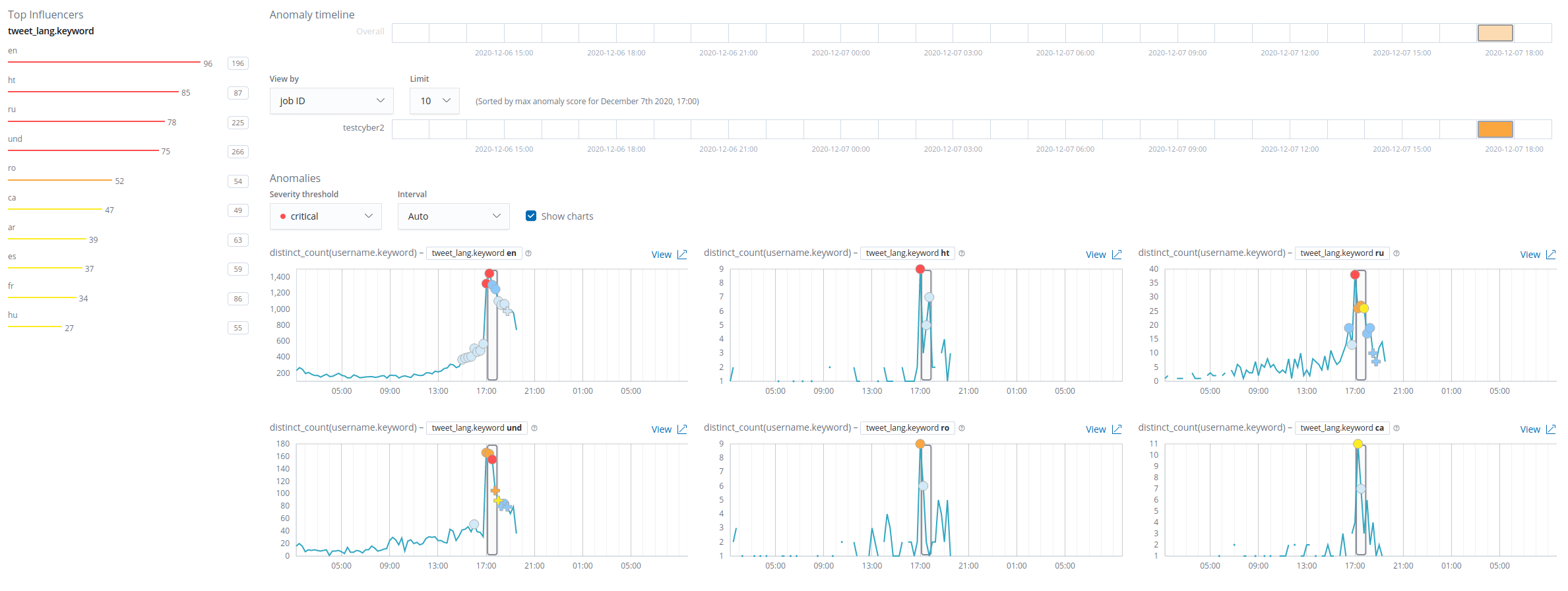
When we take a closer look by selecting the distinct users who send English tweets, we can see something happened around 17:00 GMT. (PS: it was the preloading start on Steam and Epic.)